در دنیای امروز که دادهها به عنوان سوخت اصلی برای تصمیمگیریهای هوشمندانه و توسعه کسبوکارها شناخته میشوند، انتخاب پایگاه داده مناسب نقشی حیاتی در موفقیت یک پروژه یا سازمان ایفا میکند. پایگاه داده، به بیان ساده، مخزنی سازماندهی شده برای ذخیره، مدیریت و بازیابی اطلاعات است. با توجه به گستردگی و تنوع دادهها، انواع مختلفی از پایگاههای داده با معماریها، قابلیتها و نقاط قوت متفاوت وجود دارند. در این مقاله، به بررسی جامع انواع پایگاه داده، ویژگیهای کلیدی و کاربردهای هر کدام میپردازیم تا شما را در انتخاب بهترین گزینه برای نیازهایتان یاری کنیم.
چرا انتخاب پایگاه داده مناسب اهمیت دارد؟
انتخاب صحیح پایگاه داده تأثیر مستقیمی بر موارد زیر دارد:
- عملکرد سیستم: سرعت و کارایی بازیابی و پردازش اطلاعات
- مقیاسپذیری: توانایی مدیریت حجم رو به رشد دادهها و کاربران
- امنیت: حفاظت از دادهها در برابر دسترسیهای غیرمجاز و تهدیدات سایبری
- قابلیت اطمینان: اطمینان از در دسترس بودن و صحت دادهها
- هزینه: هزینههای مربوط به خرید، نگهداری و توسعه پایگاه داده
- توسعهپذیری: سهولت در ادغام با سایر سیستمها و افزودن قابلیتهای جدید
انواع اصلی پایگاه داده:
به طور کلی، پایگاههای داده را میتوان بر اساس مدل دادهای که از آن استفاده میکنند، به دستههای زیر تقسیم کرد:
1. پایگاه داده رابطهای (Relational Database – RDBMS):
تعریف پایگاه داده رابطهای:
پایگاه داده رابطهای، نوعی پایگاه داده است که دادهها را در قالب جداولی سازماندهی میکند که با یکدیگر ارتباط دارند. هر جدول (Table) از ردیفها (Rows) و ستونها (Columns) تشکیل شده است. هر ردیف، یک رکورد (Record) یا نمونه (Instance) از دادهها را نشان میدهد، در حالی که هر ستون، یک ویژگی (Attribute) یا فیلد (Field) از رکورد را تعریف میکند. ارتباط بین جداول از طریق کلیدهای خارجی (Foreign Keys) برقرار میشود که به کلیدهای اصلی (Primary Keys) در جداول دیگر ارجاع میدهند.
 پایگاه داده زابطه ای[/caption]
پایگاه داده زابطه ای[/caption]مفاهیم کلیدی در پایگاه داده رابطهای:
برای درک کامل پایگاه داده رابطهای، ضروری است که با مفاهیم کلیدی آن آشنا شویم:
جدول (Table): همانطور که اشاره شد، جدول، ساختار اصلی برای ذخیره دادهها است. هر جدول دارای یک نام منحصر به فرد بوده و شامل مجموعهای از ردیفها و ستونها است.
ردیف (Row): یک ردیف، یک رکورد یا نمونه از دادهها را نشان میدهد. به عنوان مثال، در یک جدول “مشتریان”، هر ردیف میتواند اطلاعات یک مشتری خاص (نام، آدرس، شماره تلفن و غیره) را شامل شود.
ستون (Column): یک ستون، یک ویژگی یا فیلد از رکورد را تعریف میکند. به عنوان مثال، در جدول “مشتریان”، ستونهایی مانند “نام”، “آدرس” و “شماره تلفن” میتوانند وجود داشته باشند.
کلید اصلی (Primary Key): کلید اصلی، یک ستون یا مجموعهای از ستونها است که به طور منحصر به فرد هر ردیف را در یک جدول شناسایی میکند. هیچ دو ردیفی نمیتوانند مقدار یکسانی برای کلید اصلی داشته باشند. به عنوان مثال، یک شماره مشتری منحصر به فرد میتواند به عنوان کلید اصلی برای جدول “مشتریان” استفاده شود.
کلید خارجی (Foreign Key): کلید خارجی، یک ستون یا مجموعهای از ستونها در یک جدول است که به کلید اصلی در جدول دیگری ارجاع میدهد. این کلید، ارتباط بین دو جدول را برقرار میکند. به عنوان مثال، یک جدول “سفارشات” میتواند یک ستون “شناسه مشتری” داشته باشد که به کلید اصلی جدول “مشتریان” ارجاع میدهد.
رابطه (Relationship): رابطه، ارتباط بین دو یا چند جدول در پایگاه داده است. انواع مختلفی از روابط وجود دارد، از جمله رابطه یک به یک (One-to-One)، یک به چند (One-to-Many) و چند به چند (Many-to-Many).
SQL (Structured Query Language): SQL، زبان استانداردی است که برای مدیریت و دسترسی به دادهها در پایگاه دادههای رابطهای استفاده میشود. از SQL برای ایجاد، اصلاح و حذف جداول، درج، بهروزرسانی و حذف رکوردها، و استخراج دادهها استفاده میشود.
نرمالسازی (Normalization): نرمالسازی، فرایندی است برای سازماندهی دادهها در پایگاه داده به منظور کاهش افزونگی (Redundancy) و وابستگی (Dependency). این فرایند به بهبود یکپارچگی دادهها و کاهش مشکلات ناشی از بهروزرسانی و حذف دادهها کمک میکند.
مزایای پایگاه داده رابطهای:
پایگاه داده رابطهای به دلایل متعددی به عنوان یکی از محبوبترین مدلهای پایگاه داده شناخته میشود:
ساختار یافته و سازمانیافته: دادهها به صورت منظم و سازمانیافته در جداول ذخیره میشوند، که باعث سهولت در دسترسی، مدیریت و تحلیل دادهها میشود.
یکپارچگی دادهها: استفاده از کلیدهای اصلی و خارجی، تضمین میکند که دادهها به صورت یکپارچه و سازگار در سراسر پایگاه داده حفظ شوند.
قابلیت اطمینان بالا: سیستمهای مدیریت پایگاه داده رابطهای (RDBMS) معمولاً از مکانیسمهای قوی برای حفاظت از دادهها در برابر خرابیها و از دست رفتن اطلاعات استفاده میکنند.
امنیت بالا: RDBMSها امکان اعمال سیاستهای امنیتی مختلف را برای کنترل دسترسی به دادهها و محافظت از آنها در برابر دسترسیهای غیرمجاز فراهم میکنند.
استاندارد بودن: SQL، زبان استانداردی است که برای کار با پایگاه دادههای رابطهای استفاده میشود، که باعث سهولت در یادگیری و استفاده از این سیستمها میشود.
مقیاسپذیری: RDBMSها معمولاً میتوانند به خوبی مقیاسپذیر باشند و حجم زیادی از دادهها و تعداد زیادی کاربر را پشتیبانی کنند.
معایب پایگاه داده رابطهای:
با وجود مزایای فراوان، پایگاه داده رابطهای دارای برخی محدودیتها نیز میباشد:
پیچیدگی: طراحی و پیادهسازی پایگاه دادههای رابطهای پیچیده میتواند دشوار باشد، به خصوص برای پایگاه دادههایی با حجم داده بالا و روابط پیچیده.
انعطافپذیری محدود: ساختار ثابت جداول میتواند انعطافپذیری پایگاه داده را محدود کند، به خصوص در مواردی که نیاز به ذخیره دادههای غیر ساختار یافته یا نیمه ساختار یافته وجود دارد.
هزینه: RDBMSهای تجاری میتوانند بسیار گران باشند، به خصوص برای سازمانهای بزرگ با نیازهای پیچیده.
عملکرد: در برخی موارد، عملکرد پایگاه دادههای رابطهای میتواند در مقایسه با سایر انواع پایگاه داده، مانند پایگاه دادههای NoSQL، پایینتر باشد.
جایگاه پایگاه داده رابطهای در مدیریت داده مدرن:
با وجود ظهور مدلهای جدید پایگاه داده، مانند پایگاه دادههای NoSQL، پایگاه داده رابطهای همچنان جایگاه مهمی در مدیریت داده مدرن دارد. این مدل پایگاه داده به طور گسترده در کاربردهای مختلفی از جمله:
- سیستمهای مدیریت ارتباط با مشتری (CRM)
- سیستمهای برنامهریزی منابع سازمانی (ERP)
- سیستمهای مدیریت زنجیره تامین (SCM)
- برنامههای کاربردی مالی و حسابداری
- سیستمهای تجارت الکترونیک
استفاده میشود.
نمونهها: MySQL, PostgreSQL, Oracle, Microsoft SQL Server
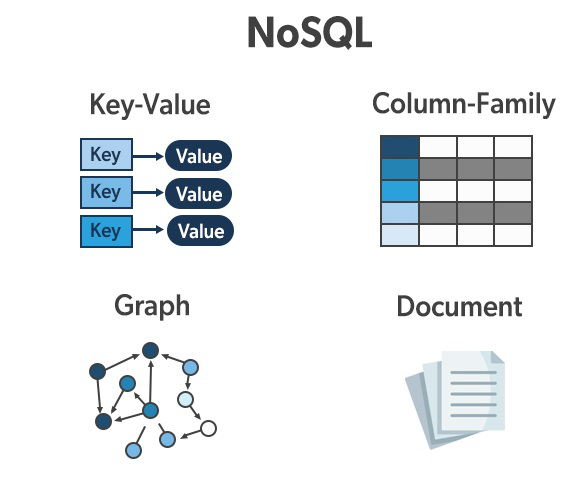
2. پایگاه داده NoSQL (Not Only SQL):
- مدل داده: پایگاه دادههای NoSQL طیف گستردهای از مدلهای داده را پشتیبانی میکنند، از جمله:
- Key-Value: دادهها به صورت جفتهای کلید-مقدار ذخیره میشوند. (مانند: Redis, Memcached)
- Document: دادهها به صورت اسناد (مانند JSON یا XML) ذخیره میشوند. (مانند: MongoDB, Couchbase)
- Column-Family: دادهها به صورت ستونی سازماندهی میشوند. (مانند: Cassandra, HBase)
- Graph: دادهها به صورت گرهها و روابط بین آنها ذخیره میشوند. (مانند: Neo4j, JanusGraph)
- زبانه پرس و جو: بسته به نوع پایگاه داده NoSQL، زبانهای پرس و جو متفاوتی استفاده میشود.
- ویژگیها:
- مقیاسپذیری افقی (Horizontal Scaling): امکان افزودن سرورهای بیشتر به پایگاه داده برای مدیریت حجم بیشتر دادهها و افزایش کارایی.
- انعطافپذیری: امکان تغییر ساختار دادهها بدون نیاز به تغییرات عمده در پایگاه داده.
- سرعت بالا: به دلیل عدم وجود محدودیتهای سختگیرانه RDBMS، سرعت خواندن و نوشتن دادهها معمولاً بالاتر است.
- مناسب برای دادههای بدون ساختار (Unstructured Data) و نیمهساختار (Semi-Structured Data): امکان ذخیره و مدیریت انواع دادهها بدون نیاز به تعریف Schema از پیش تعیینشده.
- کاربردها:
- برنامههای کاربردی وب و موبایل با حجم بالای داده و ترافیک
- شبکههای اجتماعی
- سیستمهای پیشنهاد دهنده
- تحلیل دادههای بزرگ (Big Data Analytics)
- اینترنت اشیا (IoT)
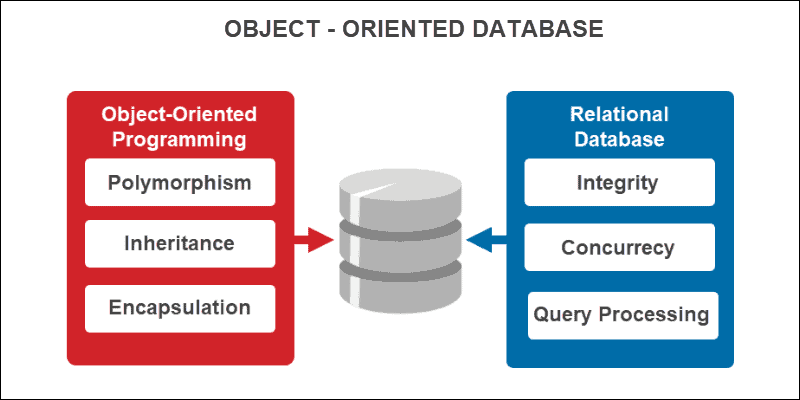
3. پایگاه داده شیگرا (Object-Oriented Database – OODBMS):
مدل داده: این پایگاه دادهها دادهها را به صورت اشیاء (Objects) ذخیره میکنند که دارای ویژگیها (Attributes) و روشها (Methods) هستند.
زبانه پرس و جو: زبانی که از مفاهیم شیگرایی پشتیبانی میکند.
ویژگیها:
- وراثت (Inheritance): امکان ایجاد کلاسهای جدید بر اساس کلاسهای موجود.
- کپسولهسازی (Encapsulation): مخفی کردن جزئیات داخلی دادهها از دید کاربر.
- چندریختی (Polymorphism): امکان استفاده از یک روش برای انواع مختلف دادهها.
کاربردها:
- سیستمهای مهندسی (CAD/CAM)
- سیستمهای شبیهسازی
- برنامههای چندرسانهای
نمونهها: GemStone/S, ObjectDB
4. پایگاه داده گراف (Graph Database):
مدل داده: دادهها به صورت گرهها (Nodes) و روابط (Relationships) بین آنها ذخیره میشوند. گرهها نشاندهنده موجودیتها و روابط نشاندهنده ارتباط بین آنها هستند.
زبانه پرس و جو: Cypher (برای Neo4j) و Gremlin از جمله زبانهای پرس و جوی رایج برای پایگاه دادههای گراف هستند.
ویژگیها:
- مناسب برای دادههای مرتبط: برای تحلیل ارتباطات پیچیده بین دادهها ایدهآل است.
- سرعت بالا در پیمایش روابط: پیمایش روابط بین دادهها به مراتب سریعتر از پایگاه دادههای رابطهای است.
- انعطافپذیری: امکان افزودن گرهها و روابط جدید بدون نیاز به تغییر ساختار کلی پایگاه داده.
کاربردها:
- شبکههای اجتماعی
- سیستمهای پیشنهاد دهنده
- کشف تقلب
- مدیریت دانش
- تحلیل شبکههای ارتباطی
نمونهها: Neo4j, JanusGraph, Amazon Neptune
5. پایگاه داده مبتنی بر زمان (Time-Series Database – TSDB):
مدل داده: این پایگاه دادهها برای ذخیره و مدیریت دادههای سری زمانی (Time-Series Data) بهینه شدهاند. دادههای سری زمانی شامل مقادیری هستند که در طول زمان ثبت شدهاند.
زبانه پرس و جو: بسته به نوع پایگاه داده، زبانهای پرس و جوی متفاوتی استفاده میشود.
ویژگیها:
- بهینهسازی برای دادههای سری زمانی: ذخیره و بازیابی سریع دادهها بر اساس زمان.
- فشردهسازی دادهها: کاهش حجم دادههای ذخیره شده.
- تحلیل دادههای سری زمانی: پشتیبانی از توابع تحلیل دادههای سری زمانی مانند میانگین متحرک و تشخیص ناهنجاری.
کاربردها:
- مانیتورینگ سیستمها و برنامهها
- اینترنت اشیا (IoT)
- بازارهای مالی
- سنسورهای صنعتی
نمونهها: InfluxDB, Prometheus, TimescaleDB
6. پایگاه داده ابری (Cloud Database):
مدل داده: پایگاه دادههای ابری میتوانند از هر یک از مدلهای داده ذکر شده (رابطهای، NoSQL و غیره) استفاده کنند.
ویژگیها:
- میزبانی در ابر: پایگاه داده در زیرساخت ابری میزبانی میشود.
- مقیاسپذیری خودکار: امکان افزایش یا کاهش منابع به صورت خودکار بر اساس نیاز.
- دسترسی بالا: دسترسی به پایگاه داده از هر نقطه در جهان.
- مدیریت آسان: ارائه دهندگان خدمات ابری معمولاً ابزارهایی برای مدیریت و نگهداری پایگاه داده ارائه میدهند.
کاربردها:
- برنامههای کاربردی وب و موبایل
- تحلیل دادهها
- ذخیرهسازی دادهها
نمونهها: Amazon RDS, Google Cloud SQL, Azure SQL Database
نکاتی برای انتخاب پایگاه داده مناسب:
انتخاب پایگاه داده مناسب نیازمند بررسی دقیق نیازمندیهای پروژه و در نظر گرفتن عوامل مختلف است. در اینجا چند نکته کلیدی را مرور میکنیم:
- نوع دادهها: نوع دادههایی که باید ذخیره و مدیریت شوند (ساختاریافته، نیمهساختاریافته، بدون ساختار).
- حجم دادهها: حجم دادههایی که باید ذخیره و مدیریت شوند و پیشبینی رشد آنها در آینده.
- نیازمندیهای عملکردی: سرعت و کارایی مورد نیاز برای بازیابی و پردازش دادهها.
- نیازمندیهای مقیاسپذیری: توانایی مدیریت حجم رو به رشد دادهها و کاربران.
- نیازمندیهای امنیتی: سطح امنیت مورد نیاز برای حفاظت از دادهها.
- هزینه: هزینههای مربوط به خرید، نگهداری و توسعه پایگاه داده.
- مهارتهای تیم: دانش و تجربه تیم توسعه در کار با انواع مختلف پایگاه داده.
- نیازمندیهای سازگاری: سازگاری با سایر سیستمها و برنامههای کاربردی.
- نیازمندیهای گزارشگیری و تحلیل: نوع گزارشها و تحلیلهایی که باید از دادهها استخراج شوند.
نتیجهگیری:
انتخاب پایگاه داده مناسب تصمیمی استراتژیک است که نیازمند درک عمیق از انواع مختلف پایگاه داده، ویژگیها و کاربردهای آنهاست. با در نظر گرفتن دقیق نیازمندیهای پروژه و عوامل ذکر شده در این مقاله، میتوانید پایگاه دادهای را انتخاب کنید که به بهترین وجه نیازهای شما را برآورده سازد و به موفقیت پروژه شما کمک کند. توصیه میشود قبل از تصمیمگیری نهایی، با متخصصان پایگاه داده مشورت کرده و نمونههای اولیه را با استفاده از گزینههای مختلف آزمایش کنید. با اتخاذ یک رویکرد آگاهانه و برنامهریزی دقیق، میتوانید از قدرت دادهها برای دستیابی به اهداف کسبوکار خود استفاده کنید.
مطالب مرتبط



آخرین دیدگاهها
چگونه امتیاز دهی به یک فایل را در SharePoint فعال کنیم؟
امیرحسین غلامیانتغییر عرض نمایش ستون ها
Fletch Skinnerتغییر عرض نمایش ستون ها
Chauffina CarrID Outcome ها در Flexi task
Fletch Skinner